【東網(wǎng)技術(shù)大咖帶您走進大數(shù)據(jù)】大數(shù)據(jù)挖掘技術(shù)分享-APP推薦模型應(yīng)用
發(fā)布時間: 2016-12-23 15:49:49
新東網(wǎng)自2001年成立以來,掌握大數(shù)據(jù)、云計算、通信、物聯(lián)網(wǎng)及區(qū)塊鏈等信息技術(shù),擁有一支逾16年經(jīng)驗的強大IT團隊。為沉淀企業(yè)技術(shù)實力,繼續(xù)發(fā)揮行業(yè)優(yōu)勢,《東網(wǎng)快訊》特邀新東網(wǎng)技術(shù)大咖帶您走進這些先進信息技術(shù),揭秘新東網(wǎng)16年來的技術(shù)成果,每周五發(fā)布。
新東網(wǎng)已經(jīng)開發(fā)并運營智慧福州、智慧倉山、智慧中山、流流順、中山好生活、派金寶等平臺和App。接下來就為大家揭秘APP推薦模型應(yīng)用。
APP推薦模型訓(xùn)練時,采用了以下幾種方法:
基于項目的協(xié)同過濾算法(1-0)
基于項目的協(xié)同過濾算法(1-0)與偏好的IBCF算法相似,不同的是,算法是根據(jù)客戶是否使用item來計算不同item之間的相似性矩陣(相當(dāng)于使用余弦公式計算相似度)。由于計算時,矩陣只有1-0兩種值,存儲較小,同時1-0矩陣的矩陣計算效率較優(yōu)(矩陣的轉(zhuǎn)置,矩陣乘法以及crossprod算法),因此該算法可方便地實現(xiàn)對大量客戶的APP使用做算法推薦。
基于項目的協(xié)同過濾算法(偏好度)
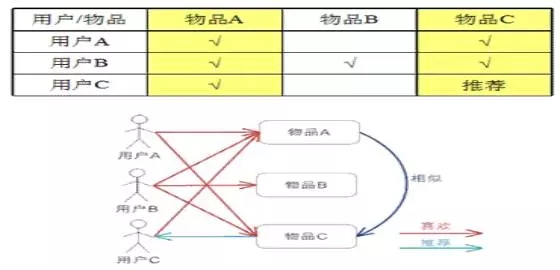
基于item的協(xié)同過濾算法,通過用戶對不同item的評分來評測item之間的相似性,計算形成item之間的相似性矩陣,根據(jù)客戶對item的偏好列表做出推薦。實際上是,給用戶推薦和他之前喜歡的item相似的item。
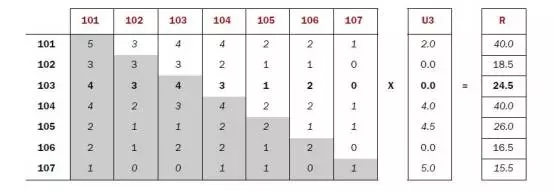
基于用戶的協(xié)同過濾算法(偏好度)
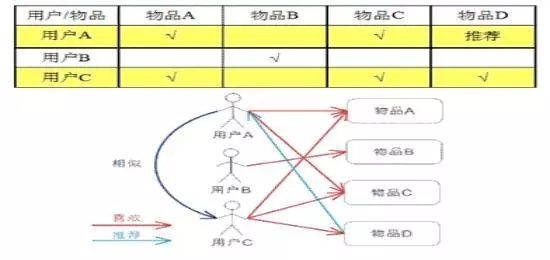
基于用戶的協(xié)同過濾算法,通過不同用戶對item的評分來評測用戶之間的相似性,計算形成用戶與用戶之間的相似性矩陣,根據(jù)最近鄰的偏好列表做出推薦。實際上是,給用戶推薦與他興趣相似的其他用戶喜歡的item。
基于關(guān)聯(lián)規(guī)則的推薦算法(1-0)
基于關(guān)聯(lián)規(guī)則的推薦(Association Rule-based Recommendation)是以關(guān)聯(lián)規(guī)則為基礎(chǔ),把客戶已使用過的item作為規(guī)則頭,規(guī)則體作為推薦對象。關(guān)聯(lián)規(guī)則挖掘可以發(fā)現(xiàn)不同item在使用過程中的相似性。關(guān)聯(lián)規(guī)則就是在一個交易類型的數(shù)據(jù)集合中統(tǒng)計使用了某itemA的交易中有多大的比例客戶同時使用了某itemB,其直觀意義在于:用戶在某時間周期內(nèi),使用某些item的同時有多大的傾向去使用另外一些item。
由于算法只對“使用過”感興趣,數(shù)據(jù)只要生成1-0(或者根據(jù)某些偏好標(biāo)準(zhǔn)判斷客戶是否使用過1-0);另外,算法只需要對樣本數(shù)據(jù)以離線的形式進行分析采集、發(fā)現(xiàn)規(guī)則,無需對全部數(shù)據(jù)集做算法計算,因此計算效率及存儲空間較優(yōu)。發(fā)現(xiàn)規(guī)則后,即可定義向滿足規(guī)則頭的客戶推薦規(guī)則體的item。
基于項目的協(xié)同過濾算法(1-0)
為測試該算法的計算效率,使用的數(shù)據(jù)為泉州-豐澤(595-501)的APP使用數(shù)據(jù),整體計算約在10分鐘內(nèi)完成,算法步驟如下:
(1)讀入交易類型數(shù)據(jù),數(shù)據(jù)形式類似user_id,app_id;
(2)將數(shù)據(jù)轉(zhuǎn)換成user_id~app_id的矩陣M,其中Rij代表客戶i對APPj是否使用過,未使用過的使用0進行填充;
(3)計算各APP(列)之間的模mod;
(4)計算各列除以該列的模,計算各APP的向量MM;
(5)使用crsooprod計算列向量的內(nèi)積,得到APP之間的相似度矩陣S;
(6)推薦列表:R = M %*% S(%*%為矩陣乘法)。
基于Popular、UBCF、IBCF偏好度的協(xié)同過濾算法
由于APP定義為客戶規(guī)模排名前100個的APP,因此,這里同時使用了流行度的算法作為IBCF、UBCF的參考算法。
使用recmomenderlab包對Popular、UBCF、IBCF三種算法進行訓(xùn)練:
(1)讀入user_id,app_id,rating的數(shù)據(jù)(實際中,Popular及IBCF算法都可對8萬個客戶進行推薦,而UBCF算法計算推薦時耗費大量時間,因此在測試的過程中,使用的4.5萬客戶的APP使用數(shù)據(jù));
(2)將數(shù)據(jù)轉(zhuǎn)化為USERID~APPID的形式,值為rating,其他用0進行填充(fill=0);
(3)將數(shù)據(jù)split為兩份,80%的數(shù)據(jù)為訓(xùn)練集,20%的數(shù)據(jù)為測試集,分別對三種算法的預(yù)測rating與實際rating做誤差計算;
(4)對三種算法做topNList的4-折cross驗證,計算混淆矩陣的TPR、FPR。
3、基于關(guān)聯(lián)規(guī)則的推薦算法
使用arules包對客戶APP使用數(shù)據(jù)進行規(guī)則發(fā)現(xiàn):
(1)讀入數(shù)據(jù):user_id,app_id;
(2)將數(shù)據(jù)轉(zhuǎn)換成transactions形式(交易類型,user_id相當(dāng)與訂單號,app_id相當(dāng)于訂單中的一種商品,一個訂單中可以有多種商品,相當(dāng)于一個客戶有多個APP使用記錄);
(3)對支持度為10%,20%,30%,以及置信度為70%,80%,90%進行規(guī)則發(fā)現(xiàn);
(4)對生成的規(guī)則進行剪枝(若規(guī)則1包含著規(guī)則2,且規(guī)則2的提升度小于等于規(guī)則1的提升度,則規(guī)則2為冗余規(guī)則,只需要保留規(guī)則1);
(5)得到規(guī)則列表。
IBCF/UBCF/POPULAR算法的誤差分析
對基于偏好度的IBCF協(xié)同過濾、UBCF、流行度算法對樣本數(shù)據(jù)(客戶數(shù)4.5萬,APP數(shù)100)實施效果評估:
(1)評分rating效果(80%訓(xùn)練集,20%測試集,預(yù)測app數(shù)目為50):
RMSE MSE MAE
POPULAR 0.5756349 0.3313555 0.3132222
IBCF 0.5347688 0.2859777 0.3108677
UBCF 0.4871018 0.2372681 0.2637091
從以上的誤差率來看,IBCF,UBCF算法的誤差率最小。
(2)4-折交叉驗證topNList效果(將數(shù)據(jù)集分為4份,運行4次,每次利用其中3份作為模型的訓(xùn)練集,1份作為模型的測試集,對模型的效果進行交叉驗證):
運行細節(jié)如下:
POPULAR run
1 [0.2sec/8.89sec]
2 [0.19sec/8.83sec]
3 [0.19sec/8.92sec]
4 [0.19sec/8.82sec]
IBCF run
1 [1.24sec/2.89sec]
2 [1.23sec/2.88sec]
3 [1.22sec/2.89sec]
4 [1.26sec/2.88sec]
UBCF run
1 [0.17sec/299.39sec]
2 [0.16sec/299.66sec]
3 [0.15sec/298.87sec]
4 [0.17sec/297.14sec]
三種算法對各topN的真正率(TPR)、假正率(FPR)如下:
從上面的輸出可以看出:
1.1、topNList推薦效果: IBCF > UBCF > Popular;
1.2、由于我們選取的APP是按照客戶規(guī)模排名選取的前100個,而流行度的推薦算法也是根據(jù)APP的客戶規(guī)模進行推薦的,因此在這里,流行度的topNList的推薦效果作為IBCF、UBCF算法的參考值;
1.3、UBCF算法在模型預(yù)測的時候,需要耗費大量的時間計算某個客戶與其他客戶的相識度(可以從模型運行的細節(jié)上看出),在這里,使用的4.5萬個客戶的效果。因此,若客戶量較大的話,如直接對1600萬APP使用客戶進行UBCF計算,計算效率和存儲空間對系統(tǒng)都是一個很大的挑戰(zhàn)。
1.4、綜上所述,在本例中,以基于流行度的算法和IBCF協(xié)同過濾算法效果最優(yōu),通用情況下,應(yīng)該考慮使用IBCF算法。
關(guān)聯(lián)規(guī)則算法得到的規(guī)則效果:
最終以30%的支持度,90%的置信度得到關(guān)聯(lián)規(guī)則的1500條規(guī)則,如下形式(詳細規(guī)則可見rulex.txt):
左件=> 右件 支持度 置信度 提升度
{815,9000382,9007654} => {9003934} 0.302 0.986 2.034
{162,20210162,700826,815,9001014,9007700} => {9008700} 0.303 0.966 1.883
規(guī)則解釋:
在所有的客戶中,有30.2%的客戶同時使用了{815,9000382,9007654}APP,其中,98.6%的客戶同時有使用{9003934}的APP,因此,可對同時使用{815,9000382,9007654}的客戶推薦{9003934}的APP。
1、由于模型訓(xùn)練使用的APP為客戶規(guī)模前100個的APP,因此流行度算法的效果最好,若改變APP的選擇定義,需要重新評估該算法的RMSE;
2、由于在我們的模型中,客戶規(guī)模>>APP數(shù)量,根據(jù)以往的經(jīng)驗,IBCF算法比UBCF算法的效果要好;
3、根據(jù)上述模型效果評估及計算效率、存儲方面綜合考慮,可選擇基于關(guān)聯(lián)規(guī)則及IBCF的協(xié)同過濾算法,或者基于流行度及IBCF的協(xié)同過濾算法,實現(xiàn)APP的混合推薦系統(tǒng)。
